Chatbot often feels like a task reserved for developers or data scientists. You imagine lines of code, complex machine learning pipelines, and hours spent debugging models that don’t behave the way you expect.
But what if I told you that none of that is necessary?
With the right tools, even non-technical users can create a truly intelligent AI assistant one that speaks in your brand’s voice, understands your products, and answers customer questions accurately. And they can do it all from their WordPress dashboard.

This article walks through a real-world example: how to build a custom chatbot from scratch using AIWU AI Copilot, a powerful plugin that allows you to train language models directly within WordPress no coding required.
We’ll start with the basics: choosing the right dataset sources, preparing them thoughtfully, and structuring them for maximum impact. Then we’ll move into training both embeddings and fine-tuned models showing how each contributes to making your chatbot smarter.
Finally, we’ll walk through deployment, testing, and iteration the steps most guides skip but which are essential for long-term success.
This isn’t just theory. This is how it works in practice.
Why Bother Building a Custom Chatbot?
Before diving into the process, let’s address the elephant in the room: why go through the trouble of building a custom chatbot when so many pre-built solutions exist?
The short answer is control.
Most off-the-shelf chatbots rely on general-purpose models. They may understand English well, but they don’t know your business. They can’t answer specific questions about your policies, products, or services unless you guide them manually every time.

A trained chatbot, by contrast, learns from your own content. It doesn’t guess at responses based on generic prompts it generates answers based on what you’ve taught it. Whether you’re answering product questions, guiding users through support issues, or automating FAQs, this level of customization makes a difference.
And with AIWU AI Copilot, you don only need technical expertise just a clear understanding of your goals and some preparation.
Let’s begin with the foundation: your dataset.
Step 1: Choosing the Right Data Source
Every good chatbot starts with good data. In our case, the goal was simple: build a bot that could answer common questions about product returns, shipping times, and order tracking.
We started by asking ourselves where that knowledge already existed not in spreadsheets or external documents, but in our existing website content.
That led us to choose site content extraction as the primary method of gathering training data. We pulled text directly from:
- Product descriptions
- FAQ pages
- Internal policy documents
- Support tickets (cleaned and anonymized)
This gave us a solid base without having to reformat anything manually. The AIWU AI Copilot interface made it easy to extract structured data from unstructured content, turning blog posts and product listings into meaningful input for the model.
Of course, we also reviewed other methods such as manual input and file uploads but site content extraction offered the best balance between relevance and convenience. Our bot wasn’t supposed to learn from random internet text; it needed to reflect our actual business.
Choosing the right source set the stage for everything else.
Step 2: Preparing the Dataset Thoughtfully
Once we had our raw material, the next step was cleaning and organizing it.
You might think that any text will work for training but nothing could be further from the truth. Quality matters more than quantity. Irrelevant or poorly structured data leads to poor results, while clean, focused datasets make the difference between a chatbot that sounds robotic and one that feels like a real part of your team.
Here’s how we approached this phase.
First, we filtered out outdated information. Policies change. Prices shift. Shipping options evolve. Feeding old content into the model would have trained it on obsolete facts something we wanted to avoid.
Next, we ensured consistency in tone. Some pages used formal language, others were casual. We adjusted entries so the bot would sound uniform across all interactions.
Then came normalization. We removed HTML tags, special characters, and inconsistent formatting. What remained was plain, readable text exactly what the embedding and fine-tuning models needed.
We also considered length. Too much text per item reduced clarity. Too little left the model guessing. We settled on a middle ground around 300–500 tokens per chunk ensuring enough context without overwhelming the system.
Finally, we validated the dataset by running test queries through it before training began. This helped us catch inconsistencies early and refine entries where needed.
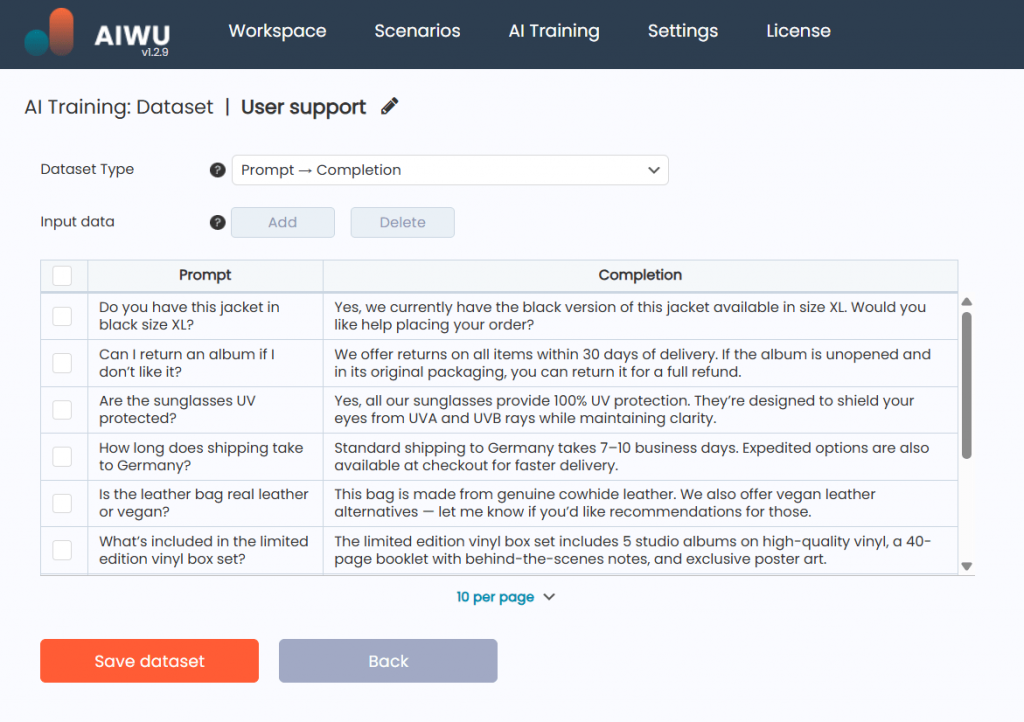
This wasn’t a quick copy-paste job. It was deliberate, thoughtful work and it paid off later during training.
Step 3: Creating Embeddings – Teaching the Bot to Understand Context
Now that we had our dataset ready, we moved to the first major step in giving our chatbot real intelligence: creating an embedding collection.
An embedding is essentially a numerical representation of meaning. Instead of working with raw words, the model transforms them into vectors high-dimensional numbers that allow semantic search. When a user asks a question, the system finds the closest match in these vectors, enabling the chatbot to retrieve relevant information automatically.
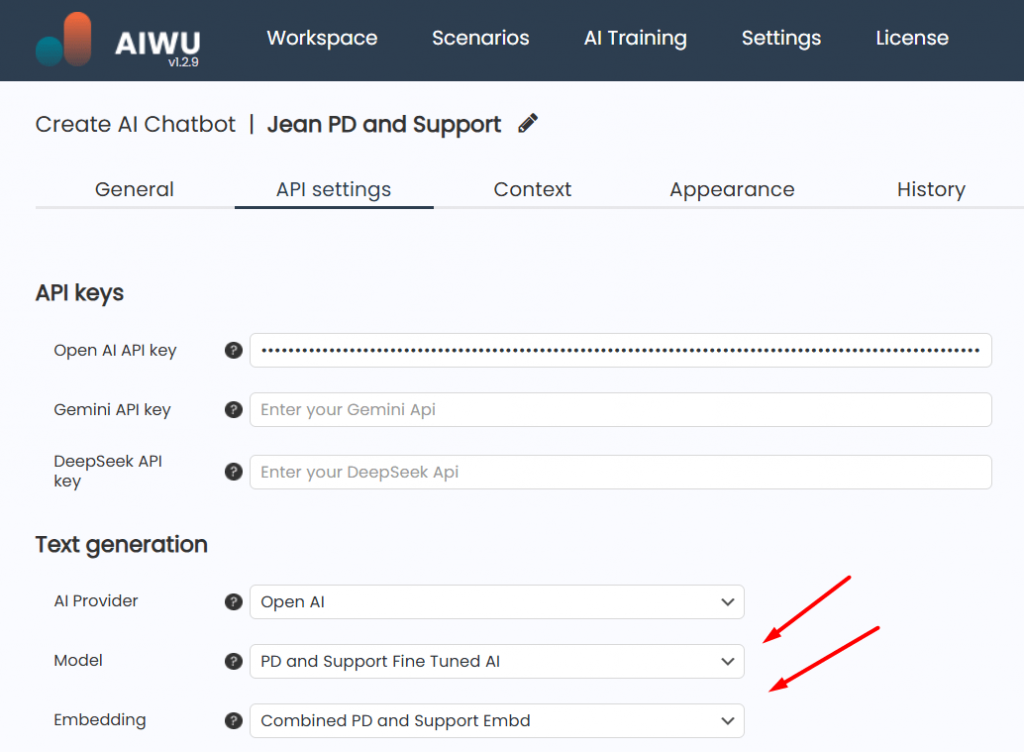
To generate embeddings, we selected the Embeddings tab inside AIWU AI Copilot and clicked Create New.
We chose our cleaned dataset and selected the OpenAI model text-embedding-3-small, which offers a strong balance between cost and performance.
Chunking strategy was important here. We opted for the default settings: 512 tokens per chunk and 50-token overlap. These values worked well for our use case, preserving context while keeping retrieval fast.
For storage, we picked Pinecone a fully managed vector database known for its ease of integration and reliable performance. We entered our API key, defined a unique index name, and tested the connection to ensure everything was configured correctly.
Then we hit Run Embedding.
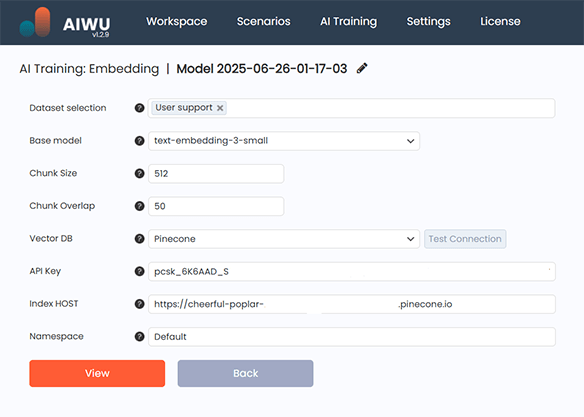
Behind the scenes, the system split our dataset into chunks, sent each to the embedding model, and stored the resulting vectors in Pinecone. Depending on the size of the dataset, this process took about an hour.
Once complete, the status changed to Ready, and we could immediately start testing how well the bot understood semantic relationships.
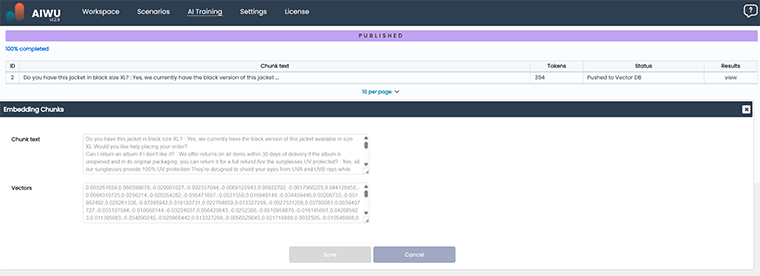
We asked questions like:
- “Can I return my order after 30 days?”
- “What happens if my shipment arrives late?”
Each query was converted into a vector and matched against the collection. The results showed that the system was already beginning to grasp meaning beyond keywords a promising sign.
But we weren’t done yet. We still needed to teach the bot how to respond not just find the right information.
Step 4: Training the Model – Fine-Tuning for Natural Responses
Fine-tuning is the process of adapting a pre-trained model to speak in your voice. While embeddings help the chatbot understand meaning, fine-tuning teaches it how to reply in a way that reflects your brand tone, internal guidelines, and preferred response style.
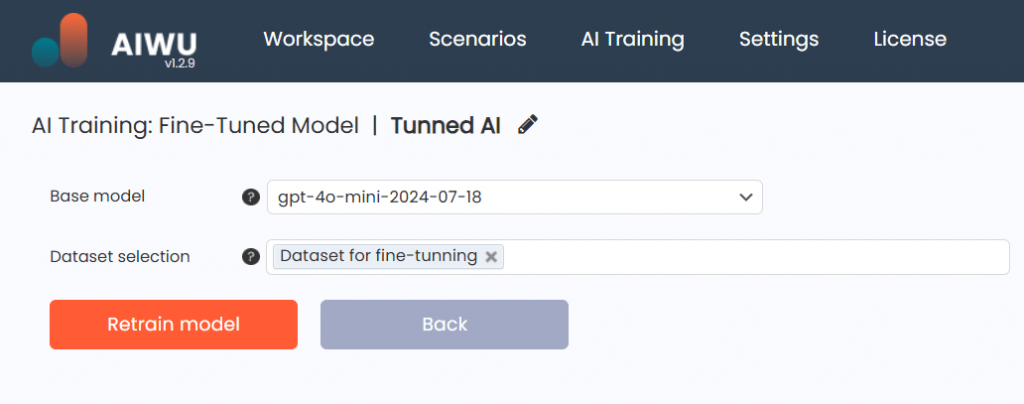
To begin, we navigated to the Fine-Tuned Models section inside AIWU AI Copilot and clicked Create New.
We entered a name for the model something descriptive, like SupportBot_v1 and selected gpt-4o-minigpt-4.1-mini at this point, given the cost implications.
Next, we chose datasets of type Prompt > Completion pairs of user questions and official responses. We had already prepared several hundred examples, extracted from real support logs and refined for consistency.
The system checked the dataset format automatically, ensuring there were no malformed entries. Once everything passed validation, we clicked Run Training.
Training took a few hours. During this time, the model adjusted its internal weights based on our examples. After completion, the new model appeared in the list with the status Ready.
We ran a series of tests using the built-in Test feature. Each prompt generated a response that sounded natural, accurate, and aligned with our brand voice.
One example stood out:
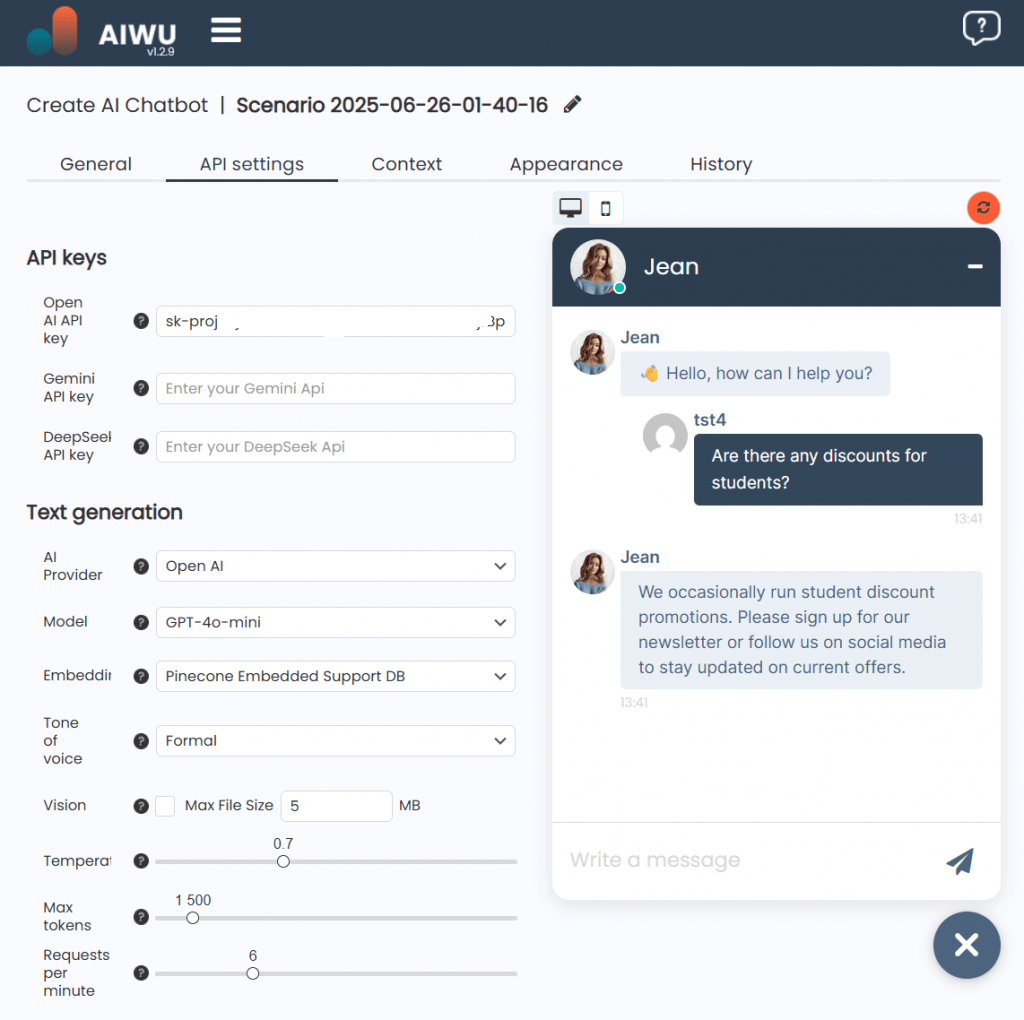
- User: “I received the wrong item. Can I exchange it?”
- Model Response: “Yes, we offer exchanges for incorrect items. Please contact support with your order number and photos of the delivered goods.”
It wasn’t just correct it followed the same phrasing and structure we used internally. That’s the power of fine-tuning: it embeds your company’s communication style into the model itself, not just the prompt.
Step 5: Deploying the Chatbot Across Your Site
Now that we had both an embedding collection and a fine-tuned model, it was time to bring everything together.
In AIWU AI Copilot, this meant opening the Chatbot Builder and selecting both components:
- The embedding collection to pull context
- The fine-tuned model to generate responses
From there, we added the chatbot widget to our product pages and support sections so it could assist in real-time conversations alongside human agents.
Deployment was smooth. There was no need for additional programming everything was handled via the WordPress UI.
First, we checked how the bot would react if we changed the question, but left it similar in meaning to what it received in the embedding.
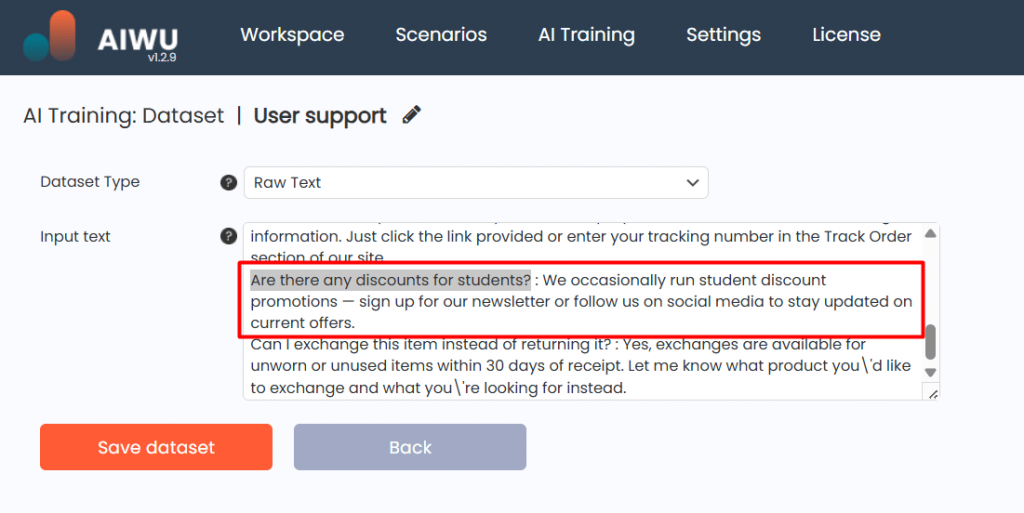
The chatbot understood perfectly well that despite the fact that the query phrase had changed, he had an answer to this question.
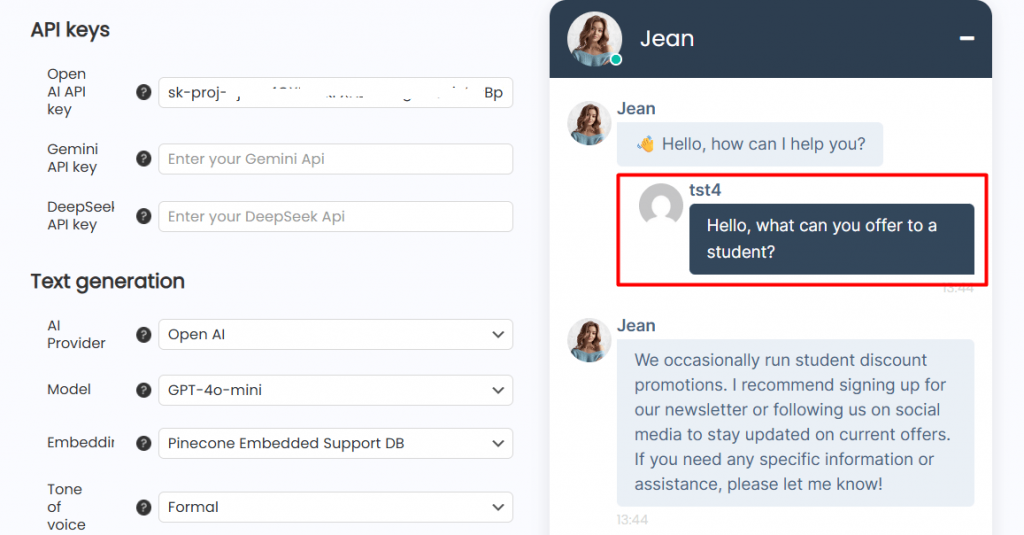
We did run a final round of tests, simulating real user interactions to ensure the bot performed consistently across different scenarios.
Some responses were too verbose. Others missed subtle details. We returned to the datasets, refined the completions, and retrained the model once more.
After the second iteration, the bot felt polished not just technically capable, but genuinely useful.
Step 6: Testing the Support Chatbot in Production
No matter how thorough your training is, the real test comes when real users interact with the bot.
We launched the chatbot in a limited capacity on a single landing page and a few product pages. We monitored engagement closely, checking:
- How often users initiated conversation
- How many questions were answered without escalation
- How many times the bot failed to understand intent
At first, the bot struggled with edge cases. For example, when users asked vague questions like “Is this product good?”, it couldn’t provide a meaningful answer. But when faced with clear, direct questions, it performed impressively.
Over the following weeks, we collected feedback and logged common failures. We added those missing cases to the dataset, retrained the model, and deployed the updated version.
Gradually, the chatbot improved. More users found it helpful. Fewer support tickets were opened for basic questions.
This is how a chatbot should evolve not as a one-time setup, but as a living asset that improves over time.
Now, if we want our chatbot to not only answer support questions but also help the user choose the right product or answer questions related to its characteristics, we must give it knowledge about our products.
Step 7: Real Product Data from Your Site
The easiest and most reliable way to build a product-aware chatbot is to pull from your own website. That way, the AI learns from up-to-date information not old manuals or third-party sources.
My case study involved a mid-sized fashion and lifestyle e-commerce site selling accessories and clothing. My goal was to train a bot that could:
- Describe product features accurately
- Suggest alternatives based on user preferences
- Help customers choose sizes
- Clarify shipping and return policies
I used AIWU AI Copilot to extract this knowledge directly from existing content.
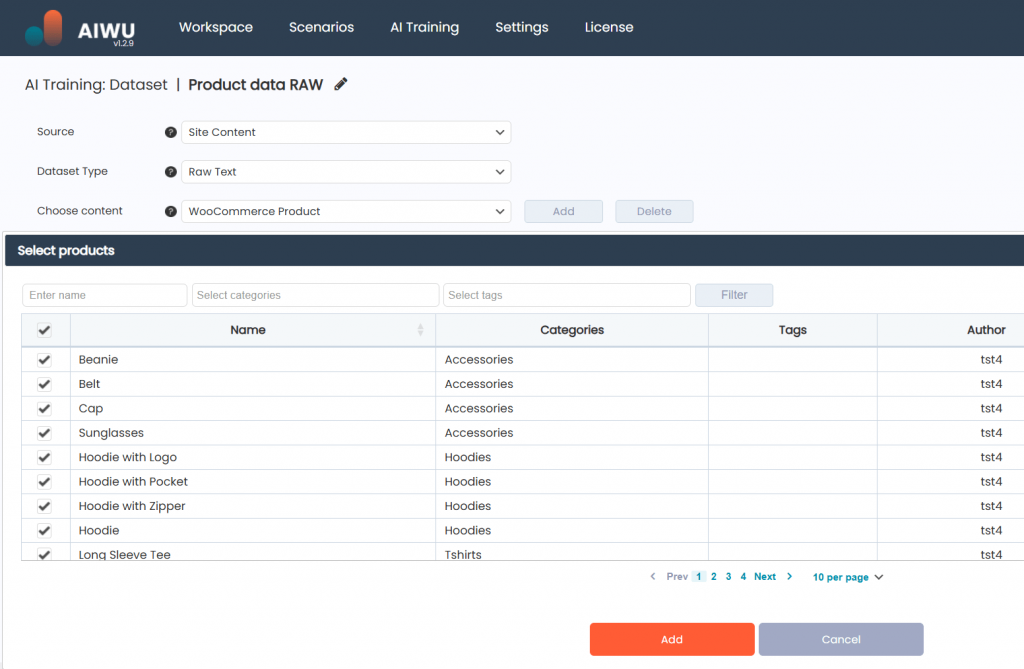
First, I went to the Datasets section inside AIWU AI Copilot and selected Site Content Extraction as the source. From there, I chose to pull data from WooCommerce products and related pages.
I made sure to include fields like:
- Product Name
- Description
- Short Description
- Tags and Categories
- Price and Stock Status
- Attributes (e.g., fabric type, size options)
Then, I applied a global instruction:
“Generate concise, accurate product summaries suitable for customer interaction.”
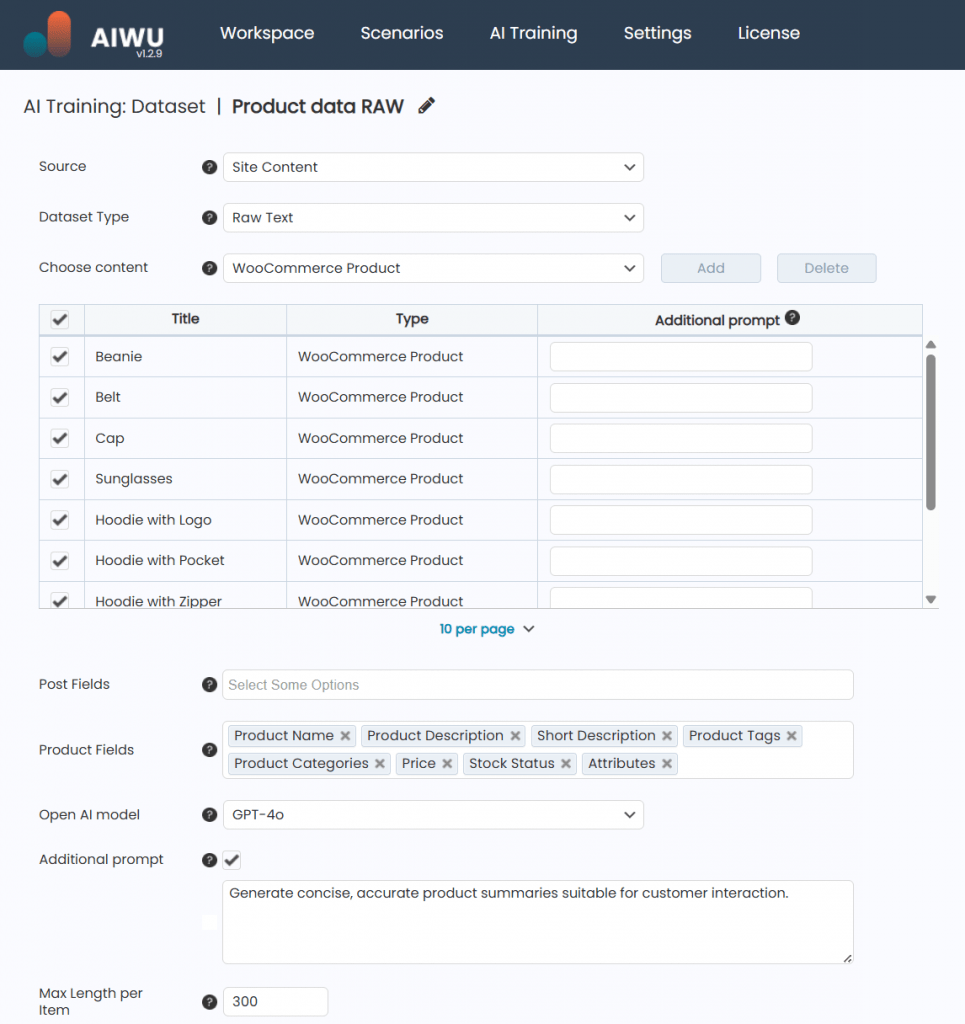
This ensured consistency across all generated examples so the bot wouldn’t switch between casual and formal tone randomly.
Once the dataset was ready, I moved on to structuring it for both embeddings and fine-tuning, depending on the use case.
Step 8: Prepare the Dataset for Training
You can’t just throw raw product data at an AI model and expect it to understand. Even the best models need structured input especially when dealing with commerce-related queries.
There are two main approaches to preparing product data for AIWU AI Copilot:
Option A: Embeddings for Semantic Understanding
Embeddings allow your chatbot to understand meaning beyond keywords. They’re ideal for tasks like:
- Finding relevant products based on natural language
- Answering complex questions about materials, use cases, or availability
- Powering recommendation systems that go beyond “customers also bought”
To build an effective embedding collection, I used datasets of type Raw Text cleaned versions of product descriptions and key attributes.
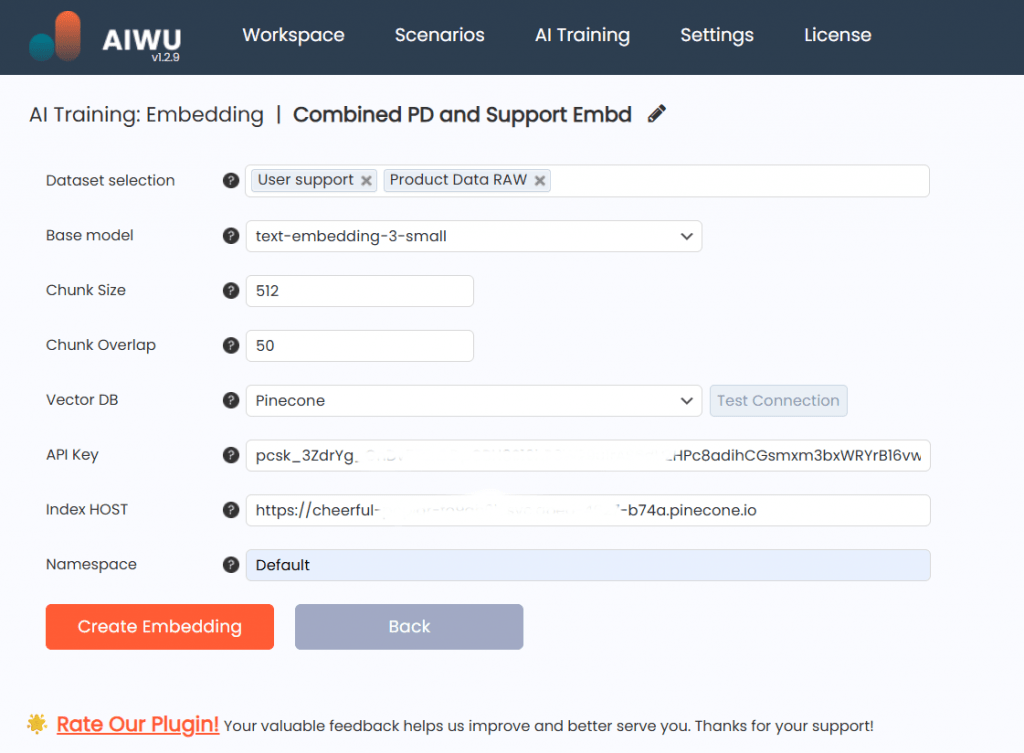
Stored in a Pinecone vector database where the chatbot could search for similarity not exact matches. For example:
- A customer asked: “Looking for a breathable scarf for winter”
- The bot retrieved entries containing words like “wool,” “lightweight,” “cold weather,” even if none of them said “breathable scarf.”
This is the power of semantic retrieval.
Option B: Fine-Tuning for Natural Responses
While embeddings help the bot find information, fine-tuning helps it generate accurate, brand-aligned responses.
Fine-tuning works best when you have a large set of Prompt → Completion pairs real examples of how your team would respond to common product questions.
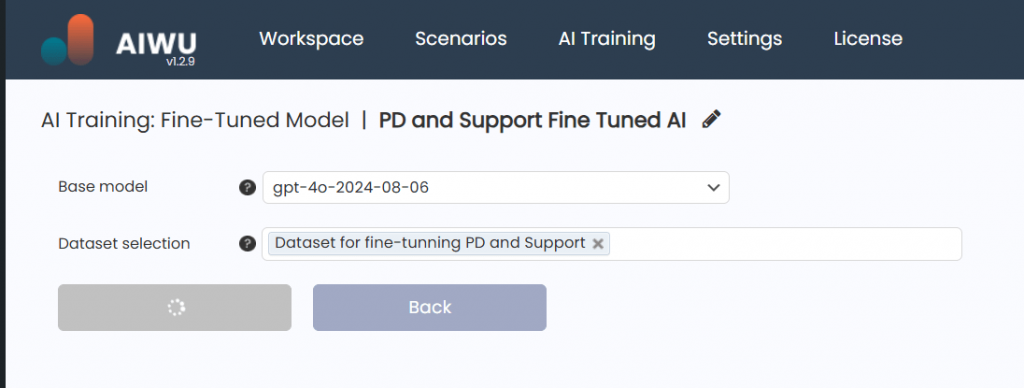
I created a CSV file with hundreds of such pairs. Each line contained a realistic customer question and the official response.
Examples included:
What's the difference between the Classic Wool Scarf and the Lightweight Travel Scarf? : The Classic Wool Scarf is made from thick merino wool and designed for cold climates. The Lightweight Travel Scarf uses a thinner blend and is better suited for layering and milder temperatures.
Is this bag water-resistant? : Yes, the outer shell has a water-repellent coating, though it's not fully waterproof.
Can I wear these boots in heavy rain? : While the boots are water-resistant, prolonged exposure to heavy rain may affect performance. Consider applying a waterproof spray before use.
What’s the difference between the Classic Wool Scarf and the Lightweight Travel Scarf? : The Classic Wool Scarf is made from thick merino wool and designed for cold climates. The Lightweight Travel Scarf uses a thinner blend and is better suited for layering and milder temperatures.
Is this bag water-resistant? Yes, the outer shell has a water-repellent coating, though it’s not fully waterproof.
Can I wear these boots in heavy rain? While the boots are water-resistant, prolonged exposure to heavy rain may affect performance. Consider applying a waterproof spray before use.
These weren’t random examples they came from real support logs and internal documentation. That made the model sound authentic and trustworthy.
After uploading the dataset, I ran the fine-tuning process via AIWU AI Copilot. Once done, the new model became available across all AIWU features including chatbots.
Step 9: Combine Embeddings and Fine-Tuned Models for Best Results
Many people treat embeddings and fine-tuning as separate tools. In reality, they work best together.
The embedding collection gave the chatbot access to product knowledge. The fine-tuned model taught it how to reply in a way that felt natural and aligned with brand tone.
So when a user asked:
“I’m looking for a lightweight jacket for city walks. Do you have anything like that?”
The system used RAG (Retrieval-Augmented Generation):
- Sent the query to the embedding index
- Retrieved the most relevant product descriptions
- Passed them along with the original question to the fine-tuned model
- Got back a coherent, personalized response
The result wasn’t just accurate it sounded like someone who really understood the product lineup.
This hybrid approach turned a generic model into a knowledgeable assistant without needing constant manual oversight.
Step 10: Test the Chatbot in Realistic Scenarios
No matter how well-prepared your data is, the only real test comes when users interact with the chatbot.
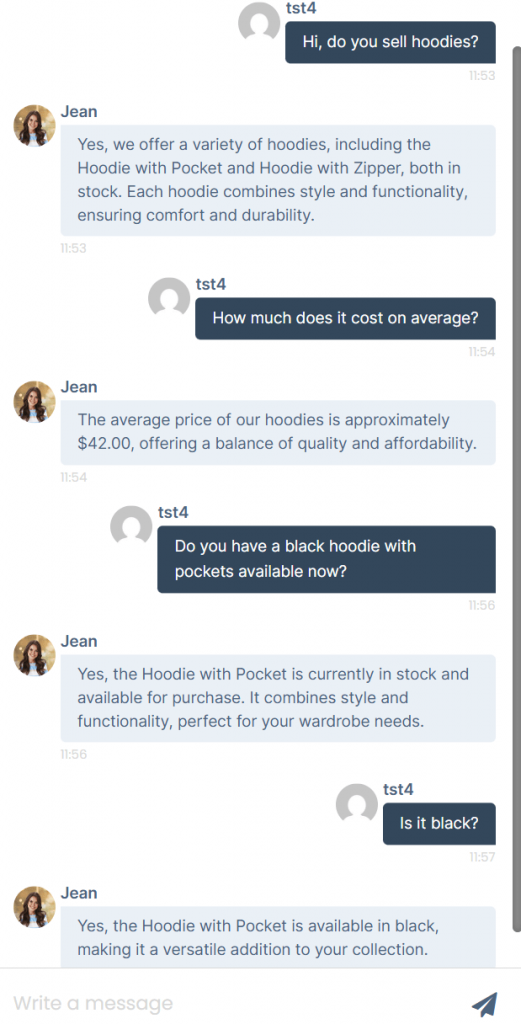
I launched the bot on a few product pages and let it run alongside human support agents. Then, I tracked:
- Which questions it handled correctly
- Where it struggled
- Whether its responses matched internal guidelines
Some results were immediate:
- The bot answered basic questions with high accuracy
- It suggested relevant products based on description matching
- It stayed consistent in tone and style
Within weeks, the chatbot handled more nuanced questions and offered better recommendations.
Step 11: Keep Updating as Your Catalog Evolves
Like any business tool, the chatbot requires ongoing attention. Content changes. Policies update. Products get discontinued or replaced. If your chatbot doesn’t keep up, it becomes irrelevant or worse, misleading.
So we established a simple maintenance cycle:
- Every month, we reviewed the top 100 questions the bot received
- We compared its responses to the official ones from our support team
- Any discrepancies led to dataset refinements and model retraining
We also don’t forget about our product database, it is constantly updated and we need to keep the AI knowledge up to date. So we also update the product data in our datasets.
We also kept a record of which versions of the model were used and when. This allowed us to roll back if a new version introduced unintended behavior.
By treating the chatbot as a living system not a static tool we ensured it remained valuable far beyond its initial launch.
How to Build a Custom Chatbot in WordPress: What Works, What Doesn’t, and Why
Creating a custom chatbot from scratch turned out to be more about discipline than complexity. Here’s what we learned along the way.
1. Dataset Quality Is Everything
Even the best model can’t overcome poor data. Typos, outdated entries, and inconsistency in tone lead to unreliable responses. Clean, representative datasets are the foundation of a successful AI assistant.
2. Embeddings and Fine-Tuning Are Complementary, Not Competing
Many people treat embeddings and fine-tuning as separate paths. In reality, they work best together. Embeddings give the bot access to your knowledge. Fine-tuning ensures it knows how to use that knowledge effectively.
3. Don’t Skip Testing
Too many teams rush through training and jump straight to deployment. This leads to surprises. Always test your bot before putting it in front of real users.
4. Iteration Beats Perfectionism
There’s no perfect dataset. No single training job gets everything right. The key is iteration refining based on real-world use, adding missing examples, and updating when things change.
5. Maintenance
AI models degrade over time. Language shifts. Knowledge evolves. User expectations change. A chatbot built once and forgotten will become outdated. Treat it like any other critical business asset maintain it regularly.
These lessons weren’t theoretical. They came from building and running a real chatbot that now handles thousands of user interactions monthly and continues to improve.
Building Smarter AI Starts with Better Preparation
If you’re reading this, you probably want to build a chatbot that actually helps your users not just repeats generic phrases or guesses at answers.
The path to that kind of AI starts with careful planning. It begins with real data, thoughtful curation, and a willingness to iterate until you get it right.
AIWU AI Copilot gives you the tools to do this without needing a line of code. But the success still depends on your ability to apply those tools wisely.
Because the truth is, anyone can install a plugin and call it a chatbot. But very few take the time to train it properly, align it with their brand, and keep it updated.
If you want your AI to feel smart not just fast start by building better datasets. Train with purpose. Test thoroughly. Maintain actively.
And then, finally, deploy with confidence.
With AIWU AI Copilot, you don’t need machine learning expertise to benefit from this process. You just need to follow the right steps and invest in quality data.
Start with clear goals.
Gather clean, representative product content.
Structure it for both embeddings and fine-tuning.
Test thoroughly before launch.
Update regularly as your inventory changes.
Do this and your chatbot won’t just answer questions.
It will understand them.
And with that understanding, it becomes a real asset not just another automated tool.