Best practices for datasets
In the world of WordPress plugins that promise to bring AI into your workflow, AIWU AI Copilot stands out by giving users real power: the ability to train custom language models using their own data without needing a line of code. But like any powerful tool, it requires thoughtful use. And nowhere is this more true than when building datasets.
Datasets are the backbone of any AI model. Whether you’re training a chatbot, generating product descriptions, or creating a smart assistant tailored to your brand, the quality of your dataset defines how well your AI will perform.
This article dives deep into what makes a dataset effective within AIWU AI Copilot , and how to avoid common mistakes that can undermine your results. We’ll walk through real-world examples, interface-specific advice, and best practices drawn from practical experience not just theory.
Start with Purpose: What Are You Trying to Teach Your AI?
Before uploading a file or clicking “Create Dataset,” ask yourself: What do I want my AI to understand? This might seem obvious, but skipping this step leads to datasets that are too broad, too narrow, or simply irrelevant.
For example, if you’re building a customer support bot, you need Q&A pairs that reflect actual user questions and official answers. If you’re training an article writer, your dataset should contain high-quality content that mirrors your brand voice and structure. If you’re creating a product recommendation engine, you’ll want to include rich metadata from WooCommerce products.
AIWU AI Copilot gives you flexibility in dataset sources manual input, files, or site content but choosing the right one depends on your goal.

Without a clear purpose, you risk wasting time collecting unnecessary data, cleaning irrelevant information, or worse training a model that looks impressive in testing but fails in real use.
Let’s look at how this plays out in practice.
Imagine you run an online store selling outdoor gear. You decide to create a chatbot to help customers find the right hiking boots based on terrain type, budget, and weather conditions. If you feed the model random product descriptions without structuring them around real customer interactions, the bot may respond politely, even cleverly but it won’t be helpful. It hasn’t learned how to answer specific questions; it’s just repeating generic phrases.
But if you start by clearly defining the bot’s purpose say, helping users choose boots based on comfort, durability, and climate then every decision about the dataset becomes easier. You’ll know what kind of conversations to collect, which examples to prioritize, and how to label responses correctly.
This clarity doesn’t just make the dataset better it makes the entire project more efficient. Without a clear goal, you risk collecting unnecessary data, wasting time cleaning irrelevant information, or worse training a model that misleads users.
Know Your Tools: Where Can You Create Datasets?
AIWU AI Copilot offers three main ways to create datasets: manually entering text, uploading files, or extracting content from your site. Each method has its strengths, and which one you choose should depend on your available resources and the type of model you’re trying to build.
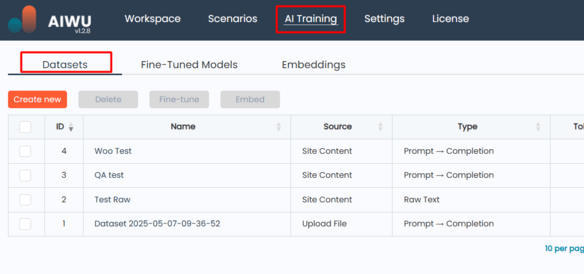
Manual input is ideal for small-scale tests where you want full control over the content. File upload works well when you already have curated material ready to go. Site content extraction is perfect when you’ve already published relevant information and don’t want to reformat it.
Knowing your tools helps you make informed decisions and avoid spending hours formatting data unnecessarily.
Let’s take a closer look at each method and how they apply to different use cases.
Manual Input: When Simplicity Works Best
Sometimes, the simplest approach is the most effective. The Text Input feature in AIWU AI Copilot lets you manually enter content directly into the plugin interface no file upload required.
When is this useful?
- For quick tests before committing to large datasets
- When you want full control over what gets included
- When working with short prompts and completions
Once you select Text Input , you’re taken to a screen where you can define whether your dataset is Raw Text (for embeddings) or Prompt → Completion (for fine-tuning). Then you add content directly into a field or table.
If you choose Raw Text , you’ll see a single multi-line field where you can paste or type unstructured text. This is ideal for feeding internal documentation, brand guidelines, or product specs into an embedding model.
If you choose Prompt → Completion , you’ll see a table where you can add multiple pairs. Each row represents a potential interaction a question and the expected response. This format is essential for training chatbots or fine-tuned models.
The key here is consistency. Two people applying different standards to the same task will produce conflicting labels, confusing the model. Clear definitions and shared understanding are key to reliable labeling.
This is why it’s important to define rules upfront. For example, should responses be formal or casual? Should they include technical terms or be simplified for general audiences? Should they link to other pages or keep everything self-contained?
These aren’t just stylistic choices they shape how your AI behaves in production.
File Upload: Bringing In Structured Data
If you already have curated content whether it’s customer service logs, product manuals, or marketing copy the File Upload feature in AIWU AI Copilot gives you a fast, flexible way to turn that data into a training set.
Supported formats include .txt, .md, .pdf, .docx for Raw Text , and .csv, .json for Prompt → Completion datasets. Each format maps automatically to a specific dataset type, though you can override these defaults if needed.
When uploading a CSV file, AIWU AI Copilot detects column separators and allows you to map columns to Prompt and Completion fields. A live preview shows how your data will be interpreted so you can catch errors early.
A typical CSV might look like this:
Question,Answer
What is your return policy?,Our standard return period is 30 days from the date of purchase.
Do you offer international shipping?,Yes we ship to over 50 countries worldwide.This format helps train models to generate accurate, context-aware replies especially useful for chatbots, FAQ assistants, or customer support tools.
For JSON files, AIWU parses the structure automatically. Just make sure your keys are consistent ("prompt" and "completion" are recommended), so the system can map them correctly.
Uploading raw text files like .txt or .pdf is great for generating embeddings or training models to understand semantic meaning. Just make sure the text is clean avoid unnecessary formatting, HTML tags, or special characters that might interfere with parsing.
Regardless of the file type, always validate your data before uploading. Large files may result in high token usage, which affects training time and cost.
Use UTF-8 encoding for best compatibility, especially when working with non-English text.
Site Content Extraction: Letting Your Website Do the Work
One of AIWU AI Copilot’s strongest features is its ability to extract data directly from your WordPress site. This is particularly useful if you already have a wealth of content published blog posts, landing pages, or product listings and don’t want to reformat it manually.
To use this feature:
- Click New Dataset and select Site Content
- Choose the content types you want to pull from: Posts , Pages , or WooCommerce Products
- Select specific items or let the system pull all content of the chosen type
- Choose which fields to include (e.g., title, description, price, categories)
- Define generation parameters like chunk size, token limits, and global instructions
Behind the scenes, AIWU uses OpenAI to process the selected content and generate either raw text or prompt-completion pairs. This is especially useful for:
- Building knowledge-aware chatbots
- Powering search engines that return relevant results, not just matching words
- Enabling Retrieval-Augmented Generation (RAG) for more accurate, data-backed responses
Once generated, you can edit the dataset manually just like in the Text Input mode giving you the flexibility to refine results.
This feature saves time while ensuring your model learns from the latest version of your content. It also ensures consistency in tone, terminology, and style something hard to achieve when sourcing data externally.
Structure Matters: Don’t Just Throw Data at the Model
One of the biggest misconceptions about AI is that more data always equals better performance. In reality, how you structure your dataset matters far more than sheer volume.
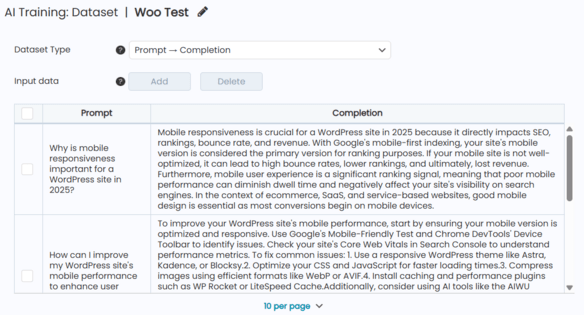
AIWU AI Copilot supports two types of datasets:
- Raw Text used for embeddings and general context understanding
- Prompt → Completion used for fine-tuning and response generation
Mixing these types or structuring them incorrectly leads to poor results.
For example:
- Using Raw Text for fine-tuning won’t work because the model needs structured examples to learn from.
- Feeding Prompt → Completion data into an embedding model creates confusion, since embeddings require continuous blocks of text, not paired entries.
When creating a dataset in AIWU, take a moment to consider:
- Is this data meant for teaching the AI context (embedding), or teaching it to respond (fine-tuning)?
- Does the format match the expected input?
- Will the model be able to extract meaningful patterns from this structure?
A well-structured dataset aligns with the logic of the task, making it easier for the model to identify relevant patterns.
This isn’t just theoretical. Real-world experience shows that teams who invest time in proper dataset design spend less time debugging later and get better results faster.
Cleanliness Isn’t Optional – It’s Essential
No dataset is perfect out of the box even those generated automatically from your own content. Cleaning your dataset isn’t glamorous, but it’s one of the most effective ways to improve model accuracy.
In AIWU AI Copilot, especially when working with auto-generated datasets from site content or uploaded files, it’s easy to overlook inconsistencies:
- Extra spaces or special characters
- Missing values in key fields
- Duplicate entries
- Misformatted prompts or completions
These issues may seem minor individually, but together they can significantly impact model performance.
After creating a dataset, always review several entries manually. Check for typos, missing fields, or formatting errors. Ensure consistency across all items.
AIWU AI Copilot allows you to edit datasets after creation use this feature to refine your data before moving on to embedding or fine-tuning.
Remember: models learn from the data they’re given. Garbage in, garbage out remains one of the most persistent truths in machine learning.
And unlike many platforms, AIWU gives you full visibility into your datasets a rare and valuable advantage.
Labeling Is More Than a Mechanical Task
If you’re using Prompt → Completion datasets, labeling becomes a central part of your process. These aren’t just random questions and answers they’re signals that teach the AI how to behave.
Labeling mistakes happen more often than people admit. They arise from unclear instructions, fatigue, or differing interpretations among labelers.
Imagine you’re training a customer service bot:
- One labeler writes: “Yes, returns are accepted within 30 days.”
- Another writes: “You can return it if it’s unused.”
Both responses are correct in different contexts, but without clear definitions, the model may become inconsistent answering correctly sometimes and erratically at others.
To reduce errors, focus on setting expectations. Create detailed annotation guidelines. Train contributors thoroughly. Use validation checks or consensus labeling. Review a random sample periodically.
AIWU AI Copilot lets you review and edit datasets after creation a great opportunity to ensure consistency and clarity in your labels.
Also, remember that AIWU allows you to add global additional prompts a powerful way to guide the model toward the tone and structure you prefer.
For example:
“Generate answers in a friendly tone. Use bullet points when appropriate. Never mention prices older than 6 months.”
This helps maintain consistency, even if the dataset was created automatically.
Balance Reflects Reality
A balanced dataset doesn’t just look neat it reflects the diversity of real-world conditions. Models trained on imbalanced data tend to perform well on common cases but fail when faced with rare or edge scenarios.
For example, a chatbot trained mostly on English queries may struggle with regional dialects or accents. A product recommendation system trained only on top-selling items may ignore niche preferences.
Balancing your dataset means ensuring that your model sees enough variation to generalize effectively.
AIWU AI Copilot makes it easy to combine multiple datasets, allowing you to mix structured Q&A pairs with raw contextual text. This hybrid approach helps the model understand both specific responses and broader themes.
It’s also possible to adjust settings like chunk size and token limits , giving you fine-grained control over how much context the model sees.
Bias Hides in Plain Sight
Bias in datasets leads to bias in models and ultimately, in decisions made by those models. This is one of the most pressing ethical concerns in AI today, and it’s not always easy to detect.
In AIWU AI Copilot, bias can creep in through historical imbalances encoded in past content, language assumptions, or sampling methods that exclude certain groups.
Even seemingly neutral data can encode societal biases. For example, job search platforms have been shown to recommend higher-paying roles more often to men due to historical patterns encoded in the data.
To combat bias, you must audit your data for representation gaps. Test models across subgroups. Involve diverse perspectives in data collection and labeling. Consider fairness-aware algorithms or regularization techniques.
AIWU AI Copilot gives you full visibility into your datasets use that transparency to check for unintended patterns or skewed representations.
Iteration Is the Only Way Forward
Finally, remember that dataset creation isn’t a one-time event it’s a continuous process.
Models degrade over time as the world changes. Customer preferences shift, language evolves, and new edge cases emerge. To keep your AI performing well, your datasets must evolve too.
Set up processes to regularly review and update your data. Monitor model performance and identify drift. Collect feedback from users and operators. Retrain models with fresh, representative data.
AIWU AI Copilot supports versioned datasets and retraining workflows use these features to maintain relevance and reliability over time.
By treating datasets as living assets rather than static files, you ensure your AI remains useful and trustworthy long after deployment.
Going Deeper: Practical Examples from Real Use Cases
Now that we’ve explored core principles, let’s look at some real-life scenarios where these best practices come into play.
Example 1: Training a Customer Support Chatbot
You run an e-commerce site selling electronics and want a chatbot that answers common questions about warranties, returns, and product specs.
Your team starts by uploading a CSV file with 500 Q&A pairs. But after deploying the bot, you notice it frequently gives outdated answers or misses nuances in customer intent.
Why? Because the dataset wasn’t reviewed for consistency. Some entries were written months ago, and others weren’t approved by the support team.
To fix this, you decide to review a random 10% of the dataset. You remove outdated or inaccurate entries. You standardize tone and structure. You run test queries to evaluate performance.
Using AIWU AI Copilot’s built-in editing tools, you refine the dataset before retraining the model. The improvement is immediate the bot now sounds more confident, more accurate, and more aligned with your brand.
Example 2: Generating Product Descriptions
You manage a clothing store with hundreds of SKUs and want to automate product descriptions to save time and maintain consistency.
Instead of hiring a copywriter, you decide to train a fine-tuned model using existing product descriptions pulled from your WooCommerce database.
You use AIWU AI Copilot’s site content extraction feature to generate a dataset from your product pages. You select fields like:
- Product Name
- Description
- Tags
- Categories
- Price
Then you apply a global instruction:
“Generate concise, brand-aligned product descriptions. Avoid markdown. Keep under 150 words.”
The first round of results is promising but not perfect. Some descriptions repeat the same phrases, while others miss key selling points.
So you refine the dataset by filtering out low-quality or duplicated entries. You add more variety by including seasonal items. You adjust the global prompt to emphasize unique features.
With these changes, the next generation is much stronger and you’ve saved dozens of hours of manual writing.
Great Models Come From Great Datasets
We often talk about models as if they’re the stars of the show deep neural networks, transformer architectures, hyperparameter tuning. But behind every successful AI application lies something quieter, less glamorous, and far more foundational: the dataset.
A well-built dataset is like a strong foundation for a house. It may not be visible once the model is deployed, but without it, everything else risks collapse.
Great datasets aren’t defined by size alone they’re defined by clarity of purpose, thoughtful structure, clean execution, and conscious design. They’re built not just for the present, but for the future documented, versioned, and maintained with care.
If you’re serious about building AI that works really works start by building better datasets. Because no matter how advanced your model becomes, it can only rise as high as the data beneath it allows.
And with AIWU AI Copilot , you have the tools to do exactly that thoughtfully, intentionally, and with real impact.