Fine-Tuning: How to Train Your Own Custom AI Model in AIWU AI Copilot
If you’re reading this article, there’s a good chance you want to train your own custom AI model using AIWU AI Copilot. You’re not looking for vague theory or general ideas about fine-tuning you want to know exactly how to do it within the plugin interface.
That’s why we’ll start with the practical steps the part you’ll actually use in your WordPress dashboard. After that, we’ll dive into the why, the how it works, and the best practices that separate good results from great ones.
Let’s begin with what matters most:
How to Create a Fine-Tuned Model in AIWU AI Copilot
To create a fine-tuned model inside AIWU AI Copilot, follow these steps directly from your WordPress admin area.
Navigate to the Fine-Tuned Models tab under the AIWU menu. This is where all your trained models are managed whether they’re still training, ready for use, or failed during processing.
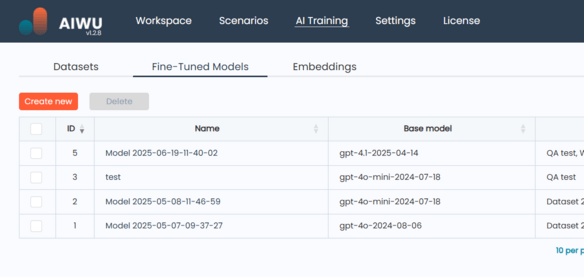
At the top of the screen, click the Create New button.
You’ll be taken to a setup page where you can:
- Enter a name for your model
- Choose a base OpenAI model (gpt-3.5-turbo, gpt-4o-mini, etc.)
- Select one or more datasets of type Prompt → Completion with status Ready
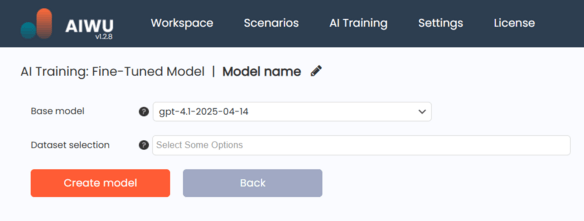
Make sure the datasets you choose are relevant to your goal. For example, if you’re building a customer support bot, select datasets containing real user questions and official answers. If you’re creating a product description assistant, pick datasets generated from WooCommerce products or marketing content.
Once everything is set, click Create model.
The system will send your dataset to OpenAI’s API and initiate the training process. Depending on the size of the dataset and current OpenAI queue times, this may take anywhere from 1–4 hours.
During this time, the model status will change to Training. Once complete, it will switch to Ready, and you’ll be able to test and deploy it immediately.
Before diving deeper into the theory and best practices behind this feature, let’s explore what happens next and how to make the most of your new model.
Testing and Using Your Fine-Tuned Model
After training completes, you need to check your model responds.
This lets you verify:
- Whether the model learned your tone and style
- If responses align with your brand voice
- Whether factual accuracy improved compared to the base model
If the results aren’t quite right, don’t worry retraining is part of the process. You can return to your dataset, refine entries, and run training again until the model behaves as expected.
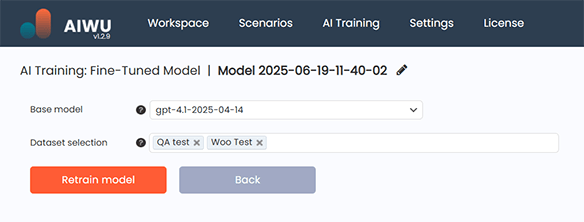
Once satisfied, your model becomes available across AIWU AI Copilot features wherever OpenAI models are used including chatbots, content generation tools.
Just open any AI-powered feature, and you’ll find your custom model listed alongside standard options. Select it, and the system will generate output based on your training data not generic defaults.
What Is Fine-Tuning – and Why Does It Matter?
Fine-tuning is the process of adapting a pre-trained language model to perform better on specific tasks by training it on additional domain-specific data. Unlike prompt engineering where you guide the model at inference time fine-tuning changes the model itself, at least partially, so it learns patterns directly from your content.

Imagine running a customer support portal and wanting your chatbot to respond like your team does. Instead of crafting elaborate prompts every time, you can show the model hundreds or thousands of real examples of how your team replies to different questions and let the model learn from them directly.
That’s the power of fine-tuning: it gives you the ability to shape the behavior of a general-purpose model based on your own voice, tone, and knowledge.
It’s not about replacing the original model, but refining it like hiring a talented writer and giving them a style guide to follow. The writer already knows how to write, but now they know how you want things written.
When Should You Fine-Tune?
Despite its benefits, fine-tuning isn’t always the best choice. In fact, for many tasks, carefully crafted prompts combined with retrieval-augmented generation (RAG) may be enough.
So how do you know if your use case calls for fine-tuning?
One sign is consistency. If you find yourself repeatedly tweaking prompts to get the same type of output adjusting tone, format, or structure it might be time to consider training a custom model instead. Another indicator is accuracy. If your AI needs to reflect internal policies, technical specifications, or brand guidelines with high precision, fine-tuning allows you to embed those rules directly into the model’s behavior.
Also, consider volume. If you have a large, stable set of training examples say, hundreds or thousands of question-answer pairs then fine-tuning becomes a viable investment. But if your data is sparse or constantly changing, it might be wiser to stick with prompt engineering or embeddings-based approaches for now.
Understanding the Inputs: What Goes Into a Good Fine-Tuning Dataset
A fine-tuned model is only as good as the data it was trained on. That’s why understanding what makes a dataset effective is critical.
The standard format for fine-tuning with OpenAI is simple: a list of instruction-following pairs. Each entry contains:
- A prompt typically a question or request
- A completion the desired response
These pairs form the backbone of the training process. The model sees thousands of these examples during training and gradually learns to mimic the style, structure, and content of the completions.
But not all datasets are created equal. Here’s what separates a useful training set from one that leads to poor performance.
First, relevance. Every example must align closely with the use case you’re targeting. Training a customer service bot with random Reddit comments won’t help it sound professional it’ll teach it slang and off-topic replies.
Second, consistency. If some responses are formal and others are casual, the model will struggle to pick up a clear pattern. Establish a tone and stick to it.
Third, quality. Typos, grammatical errors, and vague responses don’t just reduce clarity they confuse the model. It ends up learning from noise instead of signal.
Fourth, diversity. Even within a consistent tone, you need variation. If every completion looks identical, the model won’t generalize well to new inputs. It’ll start repeating phrases verbatim instead of generating fresh, appropriate responses.
And finally, size. While you can fine-tune a model with just a few hundred examples, the more high-quality data you provide, the better the results up to a point. Beyond a certain threshold, returns diminish. The key is not quantity alone, but the richness and representativeness of your examples.
Preparing Your Data: More Than Just Copy-Pasting
Creating a dataset might seem straightforward after all, you’re just collecting examples of what you want the model to say. But there’s more to it than meets the eye.
Start by identifying the source of your training data. If you’re building a customer support chatbot, look at past interactions, support tickets, or internal documentation. If you’re training a product recommendation engine, pull conversation logs or user queries.
Once you’ve gathered raw material, the next step is curation. This involves cleaning, filtering, and structuring the data into valid prompt-completion pairs. It’s tempting to automate this step, but human oversight is crucial. Only a person or a well-trained team can ensure that responses match your brand, avoid outdated information, and maintain a consistent voice.
Another important consideration is labeling. In supervised learning, labels aren’t just categories they’re full-text responses. This makes quality control even more essential. Two people applying different standards to the same task will produce conflicting labels, confusing the model.
To avoid this, define clear guidelines upfront. Specify whether responses should be formal or casual, include links or not, and how much detail to provide. These aren’t just stylistic choices they shape how the model behaves in production.
Once your dataset is ready, validate it. Run test prompts through the current model and see if the completions match what you expect. If not, refine the dataset before proceeding.
Training Your Model: What Happens Behind the Scenes
When you upload your dataset to AIWU AI Copilot and click “Run training,” a complex process begins behind the scenes.
First, OpenAI checks the formatting of your dataset. If any entries are malformed or inconsistent, the training job fails. So it’s important to validate your data before starting the process.
Then, the system splits your dataset into training and validation sets. The model learns from the training set and tests its progress against the validation set. This helps prevent overfitting where the model memorizes examples instead of learning generalizable patterns.
Next, the actual training begins. The model adjusts its internal weights based on the patterns it sees in your data. This process can take anywhere from a few minutes to several hours, depending on the size of your dataset and the base model you’re using.
Once training is complete, you’ll receive a new model ID. From that point forward, you can use this custom model across AIWU AI Copilot features including chatbots, content generation, and dynamic FAQs.
You can also test the model immediately. AIWU provides a test interface that lets you enter arbitrary prompts and see how your fine-tuned model responds. Use this tool to verify consistency, check factual accuracy, and identify edge cases where the model might behave unexpectedly.
If the results aren’t quite right, don’t panic. Retraining is part of the process. Refine your dataset, adjust your examples, and run training again until the model behaves the way you expect.
Real-World Applications: Where Fine-Tuning Makes a Difference
Fine-tuning shines brightest when applied to domains where consistency, tone, and specialized knowledge matter.
Take customer support. Many businesses rely on chatbots to handle common inquiries, but generic models often miss nuances. For instance, they might use the wrong terminology, fail to mention policy updates, or answer incorrectly due to outdated training.

By fine-tuning a model on real support conversations, companies can build bots that sound like their own team not a generic assistant. One e-commerce store reported a 40% reduction in repeat questions after switching from a default GPT model to a fine-tuned version trained on their own support logs.
Content creation is another area where fine-tuning delivers value. Writers who use AI tools often spend extra time editing outputs to match brand voice or formatting rules. With a fine-tuned model, that editing becomes unnecessary. The AI generates text that already follows your guidelines reducing post-processing time and improving overall efficiency.
Product recommendation engines also benefit from fine-tuning. By training a model on historical customer questions and official responses, AI systems can begin to predict not just what customers ask, but how best to answer.
One travel site used fine-tuning to train a model that could accurately describe hotel amenities, pricing tiers, and cancellation policies all while maintaining a friendly, helpful tone. The result? Higher engagement and fewer user complaints about unclear or misleading answers.
Practical Example: Fine-Tuning a Customer Support Bot
Let’s walk through a realistic scenario. Imagine you run a mid-sized online electronics store. You’ve been using AI to draft support emails, but the responses lack consistency. Some sound too robotic, others are overly casual, and a few contain outdated return policies.
You decide to fine-tune a model using your existing support logs. You extract 2,000 high-quality Q&A pairs, clean them thoroughly, and upload them into AIWU AI Copilot.
You don’t afford to wait weeks for results. You want to see improvements quickly and ideally, without hiring an ML engineer.
With AIWU AI Copilot, you upload your cleaned dataset and select the base model you want to fine-tune likely gpt-3.5-turbo unless you have a compelling reason to go with gpt-4o-mini. Then you hit “Run training” and wait.
After a few hours, your new model is ready. You test it by asking a series of questions related to shipping, returns, and product details. The responses are far more aligned with your brand than before. No more markdown, no more outdated info, and no more guessing at the correct tone.
You deploy the model to your live chatbot and notice immediate improvements. Fewer users report confusion. More questions are answered correctly on the first try. And your support team spends less time rewriting AI-generated responses.
Six months later, you update your return policy. You collect a few dozen new examples and retrain the model. The updated version goes live, and once again, your AI reflects your latest standards.
This is fine-tuning at work not as a one-time setup, but as a living, evolving asset.
Managing Fine-Tuned Models: Don’t Set and Forget
Once you’ve fine-tuned a model, your job isn’t done. Like any piece of software, AI models degrade over time. Language shifts. Policies change. Products evolve. And if your model isn’t updated accordingly, it risks becoming obsolete.
That’s why managing fine-tuned models requires ongoing attention. Regularly review model performance. Monitor user feedback. Track drift in responses. And when necessary, retrain with updated data.
AIWU AI Copilot supports versioned models, allowing you to keep track of changes and roll back if needed. This level of control is essential for production environments where reliability matters.
It’s also worth establishing a lifecycle for your models. Define how often you’ll retrain. Decide what constitutes a major update versus a minor adjustment. Document the reasoning behind each training run. This transparency builds trust and ensures continuity, even if team members come and go.
Common Pitfalls and How to Avoid Them
Despite its potential, fine-tuning is riddled with pitfalls many of which are easy to avoid with the right mindset.
The overfitting. If your dataset is too narrow, the model starts memorizing exact phrases instead of learning broader patterns. To prevent this, include diverse examples that cover variations in phrasing, intent, and context.
Bias is another concern. If your training data encodes historical imbalances for example, favoring male pronouns in leadership roles your model will reproduce that bias. Review your data carefully, and consider adding counterexamples if needed.
Finally, don’t treat fine-tuning as a one-time event. As your business evolves, so should your model. Treat it like any other business asset one that requires upgrades, and periodic reassessment.