How to Create and Use Embeddings in AIWU AI Copilot: A Practical Guide for WordPress Users
Setting Up an Embedding Collection
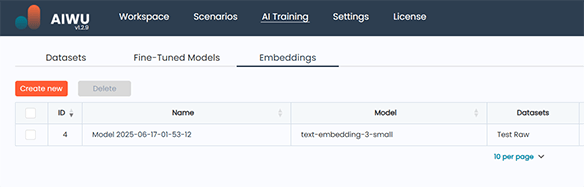
To create an embedding collection in AIWU AI Copilot, navigate to the Embeddings tab under the AIWU menu in your WordPress admin panel.
This is where all your vector-based knowledge collections are managed whether they’re used for semantic search, chatbots, or Retrieval-Augmented Generation (RAG). At the top of the screen, click the Create New button.
You’ll be taken to a configuration screen where you can define several key settings before generating your embedding.
First, give your embedding collection a meaningful name something that reflects its purpose. This helps you identify it later, especially if you end up managing multiple collections.
Next, choose one or more datasets of type Raw Text with status Ready. If you haven’t created any yet, return to the Datasets section and generate one first. The system will only allow you to proceed with datasets marked as ready otherwise, it would risk using incomplete or corrupted content.
After selecting your dataset(s), choose the OpenAI model you want to use for processing. Most users stick with text-embedding-3-small, which offers a strong balance between cost and performance. You can also opt for text-embedding-3-large if you need higher precision, though it comes at a higher token cost.
Then, you’ll specify how the system should split your text into chunks before embedding. Two parameters control this process: maximum chunk length and overlap between adjacent pieces. The default values are 512 tokens per chunk and 50-token overlap. These work well for most applications. Smaller chunks preserve precision but may lose context. Larger chunks retain meaning but reduce retrieval accuracy due to increased noise.
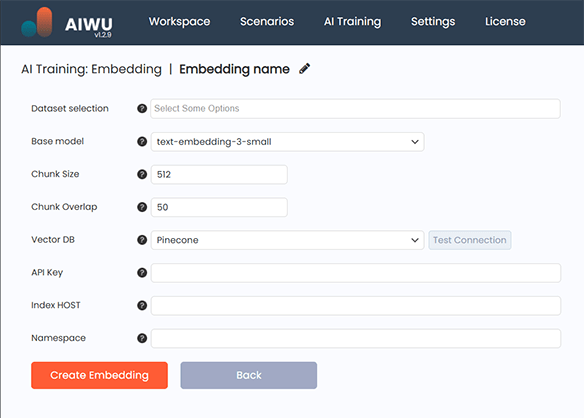
Once everything is filled out correctly, select where your vectors will be stored. AIWU AI Copilot currently supports two leading vector databases: Pinecone and Qdrant4. Both work well, but Pinecone tends to be easier for beginners due to its intuitive interface and robust support for indexing.
If you select Pinecone, you’ll enter your API Key, a unique Index Name, and optionally, a Namespace to organize subsets of data within the same index.
For Qdrant4, you’ll provide the Base API URL of your instance, an optional API Key if authentication is enabled, and a Collection Name to store your vectors.
Before proceeding, click the Test Connection button to ensure your credentials are valid and the system can communicate with the database.
When ready, click Run Embedding to start the process.
Behind the scenes, the plugin will split your dataset into manageable chunks, send each to the selected embedding model, generate numeric representations of meaning, and store those vectors in your chosen vector database. Depending on the size of your dataset and current OpenAI load, this may take anywhere from a few minutes to over an hour.
During processing, the status will show as Processing. Once complete, it changes to Ready, and the embedding becomes available for use across AIWU AI Copilot features.
At any time, you can click View to inspect individual chunks and verify that the system captured meaningful fragments not random excerpts or cut-off sentences.
Now let’s explore what embeddings really are and why they’re such a powerful tool when used correctly.
What Are Embeddings and Why Do They Matter?
In simple terms, an embedding is a numerical representation of text that captures its meaning. Instead of working with raw words or phrases, the model transforms them into high-dimensional vectors. These vectors allow AI to understand semantic similarity so two sentences with similar meaning end up close together in vector space, even if their wording is different.
For example, the phrases “How do I return my order?” and “Can I get a refund after 30 days?” might look very different in text form. But once embedded, they appear close in vector space because they express the same intent.
This ability to represent meaning numerically is what makes embeddings essential for chatbots that retrieve relevant answers based on context, search systems that find related documents regardless of exact phrasing, and content generators that pull facts and details from internal knowledge.
And with AIWU AI Copilot, you don’t need to write code to use them you just need to know how to create and manage them effectively.
How Embeddings Work Inside AIWU AI Copilot
When you run an embedding job in AIWU AI Copilot, the system follows a precise pipeline.
First, it takes your dataset usually made up of unstructured text and splits it into smaller blocks called chunks. This process ensures that no single piece is too long for the embedding model to process effectively.

Each chunk is then sent through an OpenAI embedding model typically text-embedding-3-small unless you specify otherwise. The model converts the text into a numeric vector essentially a list of numbers that reflect the meaning behind the words.
These vectors are stored in a vector database either Pinecone or Qdrant4 which allows fast retrieval of semantically similar content. When a user asks a question, the system generates an embedding for that query and searches the database for matching entries.
The most relevant results are then injected into the prompt as context before being passed to the language model. This technique, known as Retrieval-Augmented Generation (RAG), allows your AI to answer questions based on your own knowledge not just what it was pre-trained on.
It’s important to note that while embeddings aren’t visible to users, they power some of the most advanced features in AIWU AI Copilot including smart search, contextual chatbots, and dynamic content generation.
Understanding Chunk Size and Overlap
Chunking determines how your dataset is split before being turned into embeddings. While this might seem like a minor detail, it has a direct impact on how well your AI retrieves information later.
The maximum length per item defines how much text goes into each chunk. Smaller chunks mean faster retrieval and better precision, but they may lose context. Larger chunks preserve more meaning but reduce search accuracy due to increased noise.
The chunk overlap sets how many tokens are shared between adjacent chunks. This ensures continuity especially important when key ideas span multiple chunks.
Imagine you’re embedding a long article about product features. If the system splits it into chunks of 512 tokens without overlap, it might cut off mid-sentence or separate related ideas. By setting an overlap, you ensure that important concepts aren’t lost between chunks.
By default, AIWU AI Copilot uses:
- 512 tokens per chunk
- 50-token overlap
These values work well for most use cases. Only adjust them if you notice issues with retrieval quality or missing context.
Vector Databases: Where Embeddings Live
AIWU AI Copilot currently supports two leading vector databases Pinecone and Qdrant4.

One is a fully managed service known for ease of use and scalability. It’s ideal for teams who want a plug-and-play solution without server management. The other is a fast, open-source alternative with strong performance, suitable for advanced users or those already running infrastructure.
Both integrate smoothly with AIWU AI Copilot, but one is generally easier to set up for beginners.
Before proceeding, always test the connection to ensure credentials are correct and the system can communicate with the database.
Using Embeddings in Real-World Applications
Once your embedding collection is ready, it becomes available wherever AIWU AI Copilot uses external knowledge including chatbots, content generation tools, and search interfaces.
Behind the scenes, AIWU uses a technique called RAG (Retrieval-Augmented Generation). When generating a response, the system first searches your embedding collection, finds the most relevant text chunks, inserts them into the prompt as context, and sends the final request to the language model.
This allows your AI to provide accurate, context-aware responses without relying solely on what it was pre-trained on.
One practical example is a customer support bot trained on your existing documentation. Without embeddings, the bot would guess at answers based only on prompts. With embeddings, it retrieves actual content from your site and builds responses around that.
This is what makes embeddings so valuable they turn static text into active knowledge.
Best Practices for Building Effective Embedding Datasets
Creating an embedding isn’t just about clicking buttons it requires thoughtful preparation of the source data. Here’s what separates a useful embedding from one that leads to poor results.
Start with relevance. Only include content that reflects the domain you want the AI to understand. A chatbot trained on outdated manuals or irrelevant blog posts will give inconsistent results.
Clean your data thoroughly. Remove unnecessary formatting, HTML tags, and special characters. Keep your text readable otherwise, the embedding model may misrepresent meaning.
Balance depth and diversity. Include a mix of short summaries and longer explanations. If your dataset only contains brief definitions, your AI won’t understand detailed descriptions. Combining formats improves recall.
Don’t skip validation. Use the View feature in AIWU AI Copilot to inspect how your dataset was broken into chunks. Make sure the system didn’t cut off mid-sentence or lose critical context.
Monitor token usage. Large datasets consume tokens during embedding generation and that affects cost. Be selective about what you include, and avoid redundancy.
By applying these principles, you ensure your embedding collection is not just big but truly useful.
Managing Embedding Collections
Like any business asset, embedding collections require spme care.
AIWU AI Copilot lets you edit existing collections if content has changed. You can delete outdated or unused ones, test by searching for specific queries, and rebuild when your underlying content evolves.
You can also combine multiple embedding collections for instance, one for product knowledge and another for policy documents giving your AI access to broader context while maintaining modularity.
As your website grows and changes, so should your embeddings. Treat them like software versions update them when needed, document changes, and keep track of what each collection includes.
Practical Example: Training a Knowledge-Aware Chatbot
Let’s walk through a realistic scenario.
You run a tech support portal and want your chatbot to answer complex questions based on internal documentation. So far, you’ve been relying on generic prompts and keyword matching but responses are inconsistent and often incomplete.
You decide to build an embedding collection from your published articles, FAQs, and internal help guides.
Using AIWU AI Copilot, you create a Raw Text dataset from your site content. Go to the Embeddings tab and click Create New. Name the collection and select the dataset. You pick text-embedding-3-small and leave chunk size and overlap at the default values. Connect to Pinecone, entering your API key and index name. Click Run Embedding and wait.
Once the embedding is ready, you deploy it to your chatbot. Now, when users ask complex questions, the bot doesn’t guess it retrieves relevant sections from your knowledge base and generates accurate answers based on them.
Six months later, your company releases a major product update. You add new documentation, create a new embedding, and replace the old one ensuring your AI always stays current.
This is how embeddings work in practice not just as a technical feature, but as a living part of your AI system.
Recognizing Common Challenges
Even experienced users run into issues when creating embeddings for the first time. Here are the most common mistakes and how to fix them.
One frequent error is using Prompt → Completion datasets for embeddings. These are designed for fine-tuning not for semantic search. Embeddings work best with continuous blocks of text.
Another issue is choosing too large a chunk size. While bigger chunks preserve more context, they also reduce retrieval accuracy. Start with the default value and adjust only if needed.
Not reviewing chunks before deployment is another oversight. It’s easy to assume auto-generated chunks are correct but sometimes they cut off mid-sentence or mix unrelated topics.
Avoiding these pitfalls will help you build embeddings that improve your AI’s performance not just technically, but practically.
How to Improve Embedding Quality Through Better Dataset Design
While the embedding process itself is handled by AIWU AI Copilot, the quality of the output depends heavily on how you design your input dataset.
Here are some techniques used by professionals to ensure high-quality embeddings.
Focus on specific domains. Embeddings trained on broad, unfocused datasets tend to perform poorly. If you’re building a support bot, train it on support-related content only. If you’re building a product recommendation assistant, limit training to product descriptions and specifications.
Prioritize readability. Avoid markdown, tables, or special formatting. Clean, plain text ensures the embedding model sees meaning clearly, without interference from structural artifacts.
Include variation in length. Mix short and long entries. If your dataset only contains brief summaries, your AI won’t understand detailed explanations. Varying formats improves generalization.
Maintain consistency in style. Use consistent terminology, grammar, and tone throughout your dataset. Inconsistent writing confuses the model and weakens the effectiveness of semantic search.
Avoid duplication. Repeating the same idea dozens of times increases costs and reduces efficiency. Your AI doesn’t need to see the same concept over and over it needs variation to learn patterns effectively.
By following these principles, you’ll significantly increase the usefulness of your embeddings and reduce the chances of unexpected behavior in production.
How Embeddings Fit Into the Broader AI Strategy
Many people see embeddings as background infrastructure something that “just works” once set up. In reality, they’re one of the most powerful tools for making AI feel intelligent.
They act as a bridge between your content and your AI, allowing the system to “understand” meaning beyond keywords. Unlike traditional search engines, which rely on exact matches, embeddings find relevance based on context and intent.
This makes them ideal for customer support bots that pull from internal documentation, product assistants that recommend items based on user questions, content writers that pull from brand guidelines or past articles, and search tools that return meaningful results instead of just keyword hits.
In combination with other AIWU features like fine-tuned models and prompt engineering embeddings complete the picture of a truly context-aware AI assistant.
Why Embeddings Outperform Keyword-Based Systems
Traditional search engines operate on keywords. That means if a user asks, “What’s your return policy?”, the system looks for pages containing the exact phrase “return policy”. If the page says “Refund rules” instead, it won’t show up.
Embeddings solve this problem by focusing on meaning, not words.
This is especially useful in customer support systems, internal knowledge bases, dynamic content generation, and recommendation engines.
Keyword-based approaches are limited. Embeddings offer flexibility and a much deeper understanding of what users are actually asking.
Embeddings in Action: Real-World Case Studies
Let’s take a closer look at how embeddings deliver value in real-life applications.
An e-commerce company wanted to reduce repetitive support tickets. They built an embedding collection from hundreds of support logs and product descriptions.
After integrating the embedding into their chatbot, they saw a 35% drop in repeat questions. The bot now finds relevant answers faster and more accurately than before.
A digital marketing agency wanted to automate blog writing while preserving brand voice. They created an embedding from hundreds of previously approved articles.
When generating new content, the AI pulls from this embedding to ensure consistency in tone, style, and structure. Writers spend less time editing and more time refining ideas.
A SaaS platform struggled with low engagement due to poor search results. They switched to embeddings and noticed immediate improvements.
Users started finding what they were looking for even when their queries weren’t worded exactly like the content. The embedding model understood the intent behind the search, not just the literal match.
These examples show that embeddings aren’t just a technical upgrade they’re a strategic move toward smarter, more context-aware AI.
Embeddings – Deliver Real Results
You don’t need a PhD to benefit from embeddings. You just need to understand how they work and how to apply them thoughtfully.
At their core, embeddings are a way to teach your AI what matters most by turning your own content into searchable knowledge.
With AIWU AI Copilot, you can build embeddings from your WordPress content, store them in reliable vector databases, use them in chatbots, content generation, and search, and update them as your business evolves.
And none of it requires machine learning expertise.